MySQL的高可用,首先就是其可用性即数据如何持久化,其次就是主备,主从之间如何同步,通过binlog,binlog的格式对复制的影响,以及延迟的产生因素等等。
本文的逻辑参考极客时间《MySQL实战45讲》23节-28节。
MySQL的持久化
修改SQL,执行过程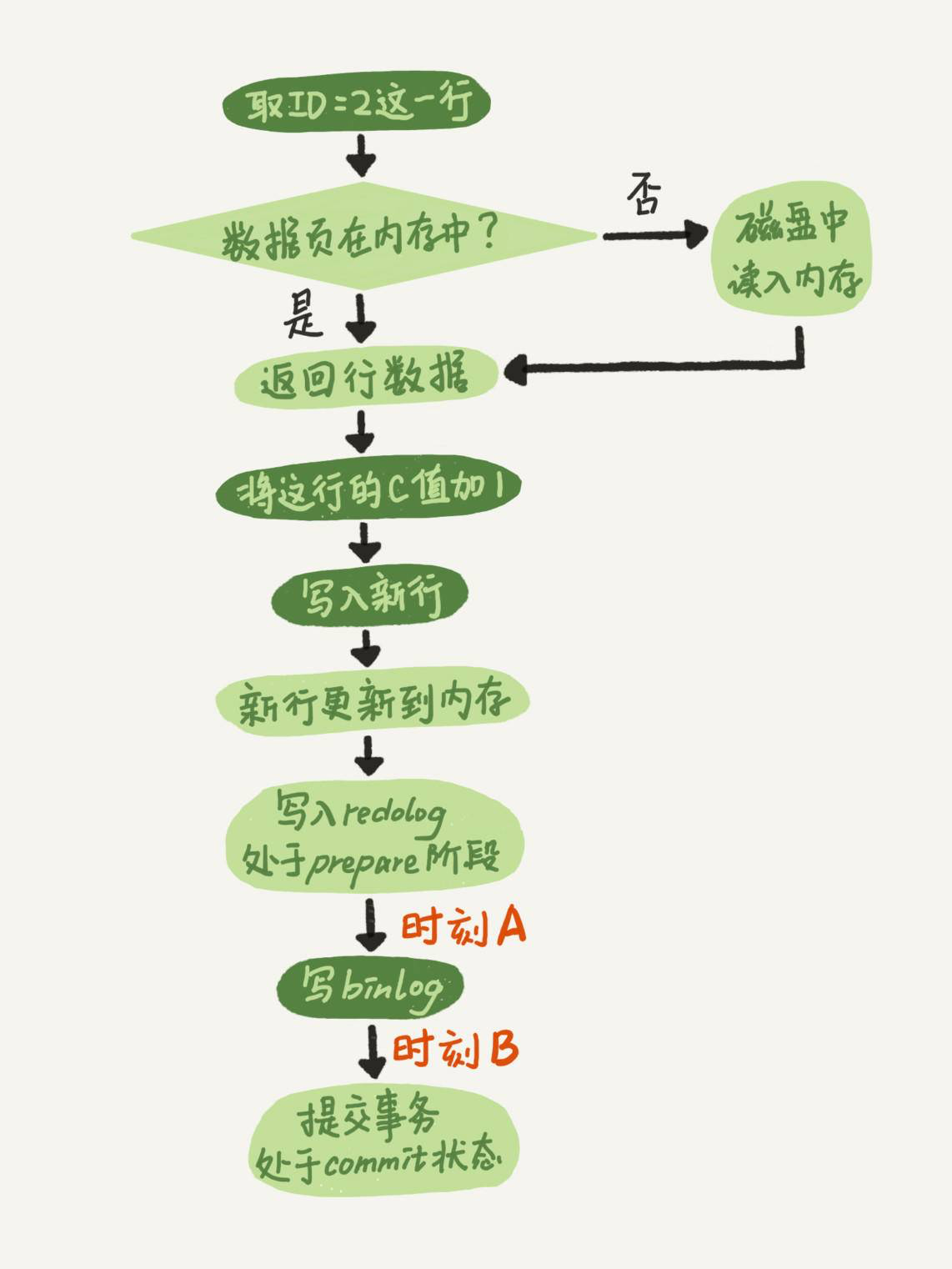
核心:时刻A,时刻B,两阶段提交。通过两阶段提交可以找回丢失的数据。
我们先来看一下崩溃恢复时的判断规则。
如果redo log里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
如果redo log里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:
a.如果是,则提交事务;
b.否则,回滚事务。
binlog 的写入逻辑:事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件。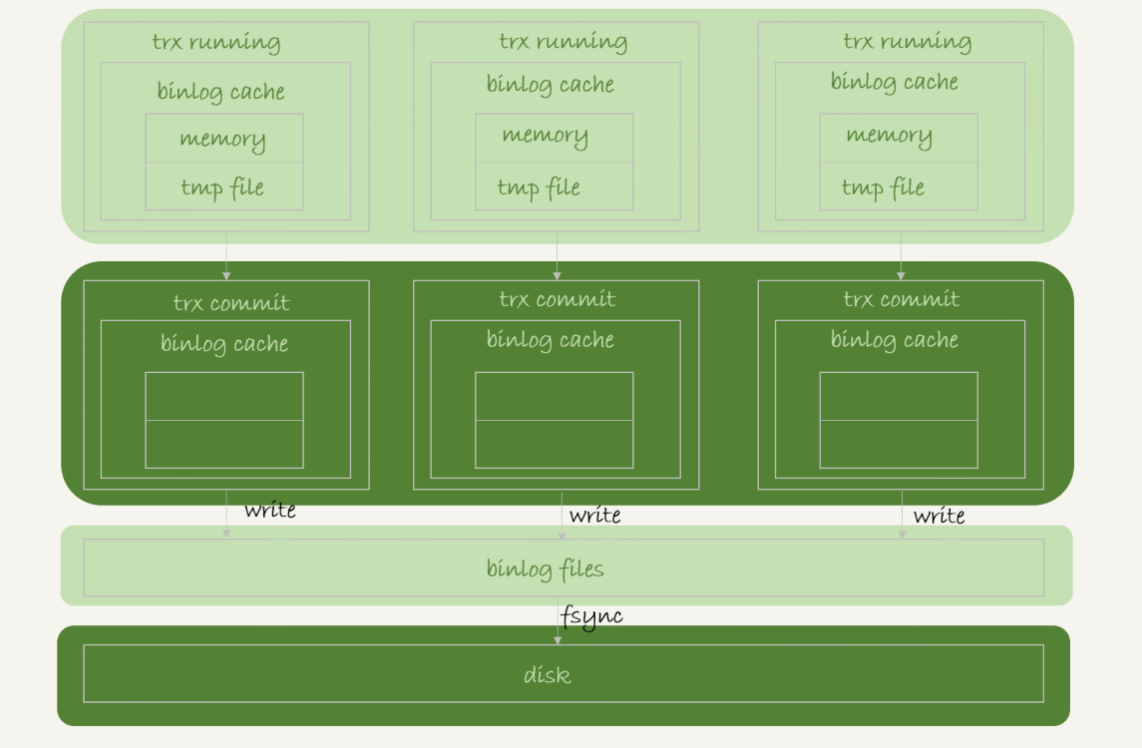
write 和 fsync 的时机,是由参数 sync_binlog 控制的:
sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
redo log写入机制: 事务在执行过程中,生成的 redo log 是要先写到 redo log buffer。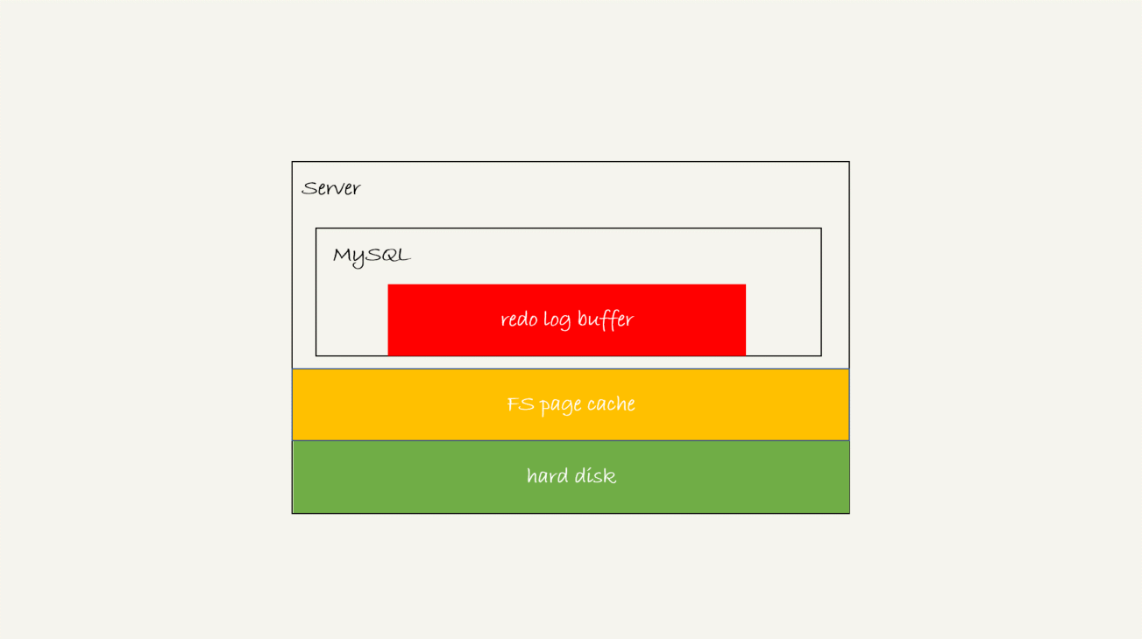
InnoDB 提供了 innodb_flush_log_at_trx_commit 参数,它有三种可能取值:
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;
- 设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。
InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 write 写到文件系统的 page cache,然后调用 fsync 持久化到磁盘。
通常我们说 MySQL 的“双 1”配置,指的就是 sync_binlog 和 innodb_flush_log_at_trx_commit 都设置成 1。也就是说,一个事务完整提交前,需要等待两次刷盘,一次是 redo log(prepare 阶段),一次是 binlog。
组提交:多个事务一起写入磁盘被称为组提交。
想提升 binlog 组提交的效果,可以通过设置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 来实现。
- binlog_group_commit_sync_delay 参数,表示延迟多少微秒后才调用 fsync;
- binlog_group_commit_sync_no_delay_count 参数,表示累积多少次以后才调用 fsync。
你在什么时候会把线上生产库设置成“非双 1”。我目前知道的场景,有以下这些:
- 业务高峰期。一般如果有预知的高峰期,DBA 会有预案,把主库设置成“非双 1”。
- 备库延迟,为了让备库尽快赶上主库。
- 用备份恢复主库的副本,应用 binlog 的过程,这个跟上一种场景类似。
- 批量导入数据的时候。
主备/主从问题
如何保证主备数据执行一致?
binlog的格式:Statement、Row、Mixed
Statement 使用会主库与备库数据不一致。大多采用ROW格式。
主备延迟
切换不同策略
可靠性优先策略:主切换readOnly,备库延迟为0进行改为master
可用性优先策略:在binlog是row,直接进行切换,数据出错会直接报出,方便修改。
实践中一般采用可靠性策略进行切换。
延迟产生原因
核心因素:主备延迟最直接的表现是,备库消费中转日志(relay log)的速度,比主库生产 binlog 的速度要慢。
导致慢的原因:
- 备库所在机器的性能要比主库所在的机器性能差
- 备库的压力大,提供更多查询
- 大事务,例如十分钟的事务,大表DDL
并行复制能力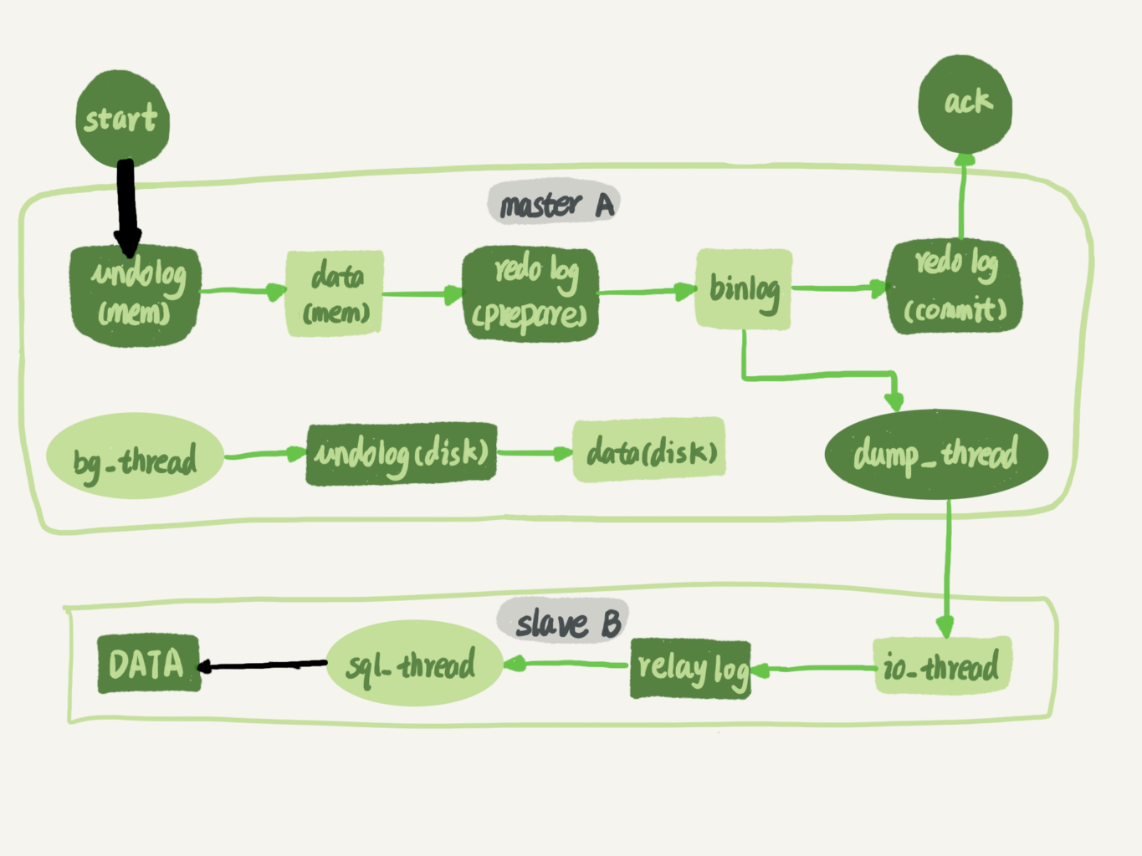
在主库上,影响并发度的原因就是各种锁了。由于 InnoDB 引擎支持行锁,除了所有并发事务都在更新同一行(热点行)这种极端场景外,它对业务并发度的支持还是很友好的。所以,你在性能测试的时候会发现,并发压测线程 32 就比单线程时,总体吞吐量高。而日志在备库上的执行,就是图中备库上 sql_thread 更新数据 (DATA) 的逻辑。如果是用单线程的话,就会导致备库应用日志不够快,造成主备延迟。在官方的 5.6 版本之前,MySQL 只支持单线程复制,由此在主库并发高、TPS 高时就会出现严重的主备延迟问题。
官方 MySQL5.6 版本,支持了并行复制,只是支持的粒度是按库并行。
MariaDB 是这么做的:
在一组里面一起提交的事务,有一个相同的 commit_id,下一组就是 commit_id+1;commit_id 直接写到 binlog 里面;
传到备库应用的时候,相同 commit_id 的事务分发到多个 worker 执行;
这一组全部执行完成后,coordinator(分发器) 再去取下一批。
MySQL 5.7 并行复制策略的思想是:同时处于 prepare 状态的事务,在备库执行时是可以并行的;处于 prepare 状态的事务,与处于 commit 状态的事务之间,在备库执行时也是可以并行的。
讲 binlog 的组提交的时候,介绍过两个参数:
binlog_group_commit_sync_delay 参数,表示延迟多少微秒后才调用fsync;
binlog_group_commit_sync_no_delay_count 参数,表示累积多少次以后才调用 fsync。
这两个参数是用于故意拉长 binlog 从 write 到 fsync 的时间,以此减少 binlog 的写盘次数。在 MySQL 5.7 的并行复制策略里,它们可以用来制造更多的“同时处于 prepare 阶段的事务”。这样就增加了备库复制的并行度。
MySQL 5.7.22 新增了一个参数 binlog-transaction-dependency-tracking,
用来控制是否启用这个新策略。这个参数的可选值有以下三种。
COMMIT_ORDER,表示的就是前面介绍的,根据同时进入 prepare 和 commit 来判断是否可以并行的策略。
WRITESET,表示的是对于事务涉及更新的每一行,计算出这一行的 hash 值,组成集合 writeset。如果两个事务没有操作相同的行,也就是说它们的 writeset 没有交集,就可以并行。
WRITESET_SESSION,是在 WRITESET 的基础上多了一个约束,即在主库上同一个线程先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序。
主从-读写分离的坑
新数据从库读取不到。
解决方案:
- 对于迅速要读的强制走主库
- 可以sleep一下进行
- 判断主备无延迟方案
针对主备延迟方案:
- 3.1 seconds_behind_master 是否已经等于0
- 3.2 对比位点确保主备无延迟
- 3.3 对比 GTID 集合确保主备无延迟
GTID:
- 3.3.1 配合 semi-sync,从库(仅一个)同步完成ack主库 (存在两个问题:一主多从的时候,在某些从库执行查询请求会存在过期读的现象;在持续延迟的情况下,可能出现过度等待的问题。)
- 3.3.2 GTID 的执行流程就变成了:trx1 事务更新完成后,从返回包直接获取这个事务的 GTID,记为 gtid1;选定一个从库执行查询语句;在从库上执行 select wait_for_executed_gtid_set(gtid1, 1);如果返回值是 0,则在这个从库执行查询语句;否则,到主库执行查询语句。